Writing containers from scratch in Go!
June 16, 2020
Okay, finally I’m here writing something technical. I’m still not sure what’s gonna be the flow but I’m keeping my hopes high (or otherwise I'll strike it once I'm done XD).
Actually this post is gonna be my talk-notes for the Liz Rice’s talk What Have Namespaces Done for You Lately? So, everything written later in the post is entirelly credited to Liz Rice who in-turn thanks Julian Friedman for the talk idea & the code snippets used inside.
Let’s get started now!
Before jumping right away into writing a container of our own from scratch, the first & the most important thing is to understand what actually a container is?
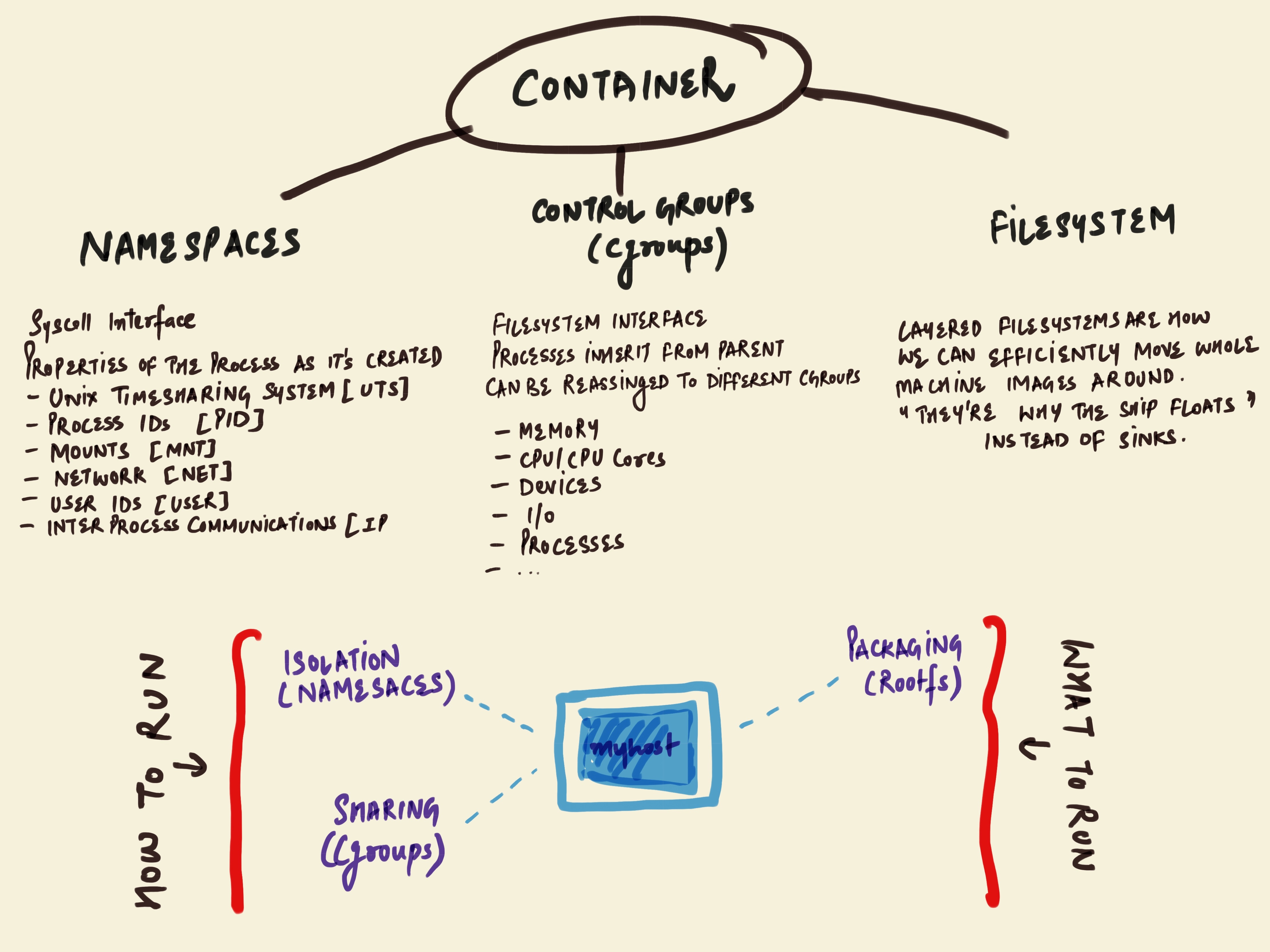
From my understanding so far, a container simply is a means for obtaining process isolation. I’m sure it is in no way close to a complete definition but definitely a broader idea. So, what completes the definition, is knowing about the following 3 things which makes up the majority of the container.
- Namespaces - What your container can see!
- Control Groups (cgroups) - What your container can use!
- layered filesystem - The home for the above two, to do all their magic.
Ok, now that our base idea is ready, and we know what elements we need to implement in order to write our container from scratch.
So, it’s a good time to jump into the actual go implementation now.
IMPLEMENTATION
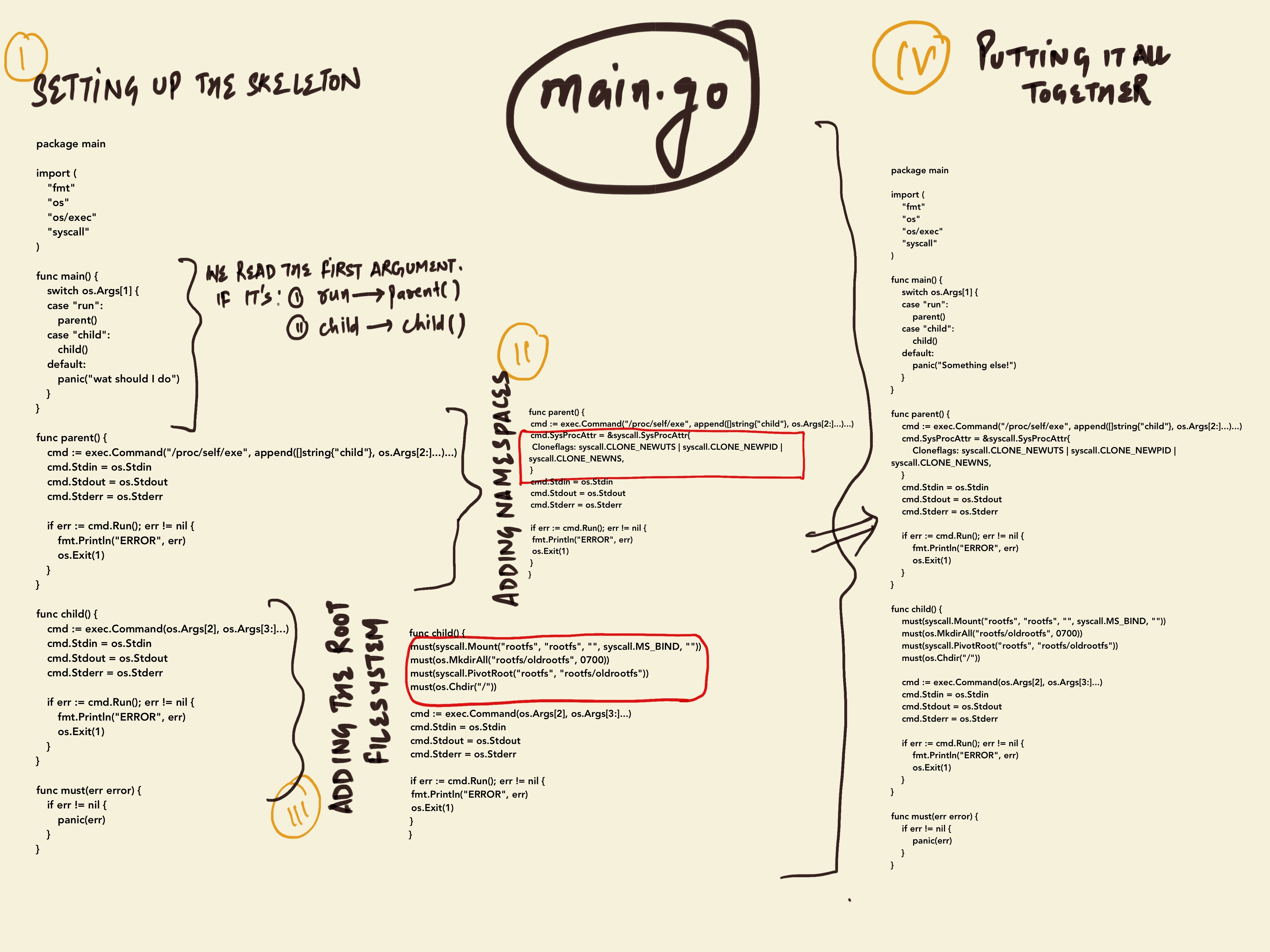
- The first and formost requirement is to import all the required modules. So, that’s what the below code block is taking care of.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
- Next up, we have a function defined as
main(). It reads the first argument (passed while running themain.gofile), checks if it is eitherrun, orchild.- If it’s
run, then run theparent()method. - Or if it’s
child, then run thechild()method.
- If it’s
func main() {
switch os.Args[1] {
case "run":
parent()
case "child":
child()
default:
panic("Something else!")
}
}
- Next, we have another function,
parent(). This function does the following:- In the first line, it runs
/proc/self/exewhich is a special file containing an in-memory image of the current executable. In other words, it re-run itself, but passing child as the first argument - In the second line, it adds
UTS,PID, andMNTnamespaces to the container. - Rest, set of
Stdin | Stdout | Stderrcommands are to display the results in the terminal. - And finally in the end, it does the caretaking for error handling.
- In the first line, it runs
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
- Then, we’ve this another function defined as
child()which does the following:- The first line change the default user prompt hostname to
container, so we can visualize that we are inside our newly created container. - The next two lines tell the OS to move the current directory at
/torootfs/oldrootfs, and to swap the new rootfs directory to/. - Then in the next two line, once the
pivotrootcall is complete, the/directory in the container will refer to the rootfs. - Rest part is same as we discussed in the above function.
- The first line change the default user prompt hostname to
func child() {
must(syscall.Sethostname([]byte("container")))
must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, ""))
must(os.MkdirAll("rootfs/oldrootfs", 0700))
must(syscall.PivotRoot("rootfs", "rootfs/oldrootfs"))
must(os.Chdir("/"))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
- And finally the last
must()function. It’s a part of the skeleton code, and it basically wraps all the syscall & os module commands for error handling purpose.
func must(err error) {
if err != nil {
panic(err)
}
}
CREATING CGROUPS (EXTRA)
- The below is a function
cg()which basically creates a new cgrouppidsfor our newly created container.
(According to our flow, it should be invoked inside the child() function.)
func cg() {
cgroups := "/sys/fs/cgroup/"
pids := filepath.Join(cgroups, "pids")
os.Mkdir(filepath.Join(pids, "priyanka"), 0755)
must(ioutil.WriteFile(filepath.Join(pids, "priyanka/pids.max"), []byte("20"), 0700))
// Removes the new cgroup in place after the container exits
must(ioutil.WriteFile(filepath.Join(pids, "priyanka/notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(pids, "priyanka/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
INITIALISING THE CONTAINER
- Mark that the
main.gofile needs to executed from a user with root privileges. - You can verify whether the new container is being created or not via running example commands like:
$ go run main.go run echo Hello World
$ go run main.go run /bin/bash
That’s all about what our go program does in process of creating a whole new container from scratch.
During the talk, Liz talks about fork bomb which basically is this :(){ :|: & }; : command. It basically creates infinite numbers of processes to check whether the cgroup created above limits the number of process running inside the container or not. It basically is a way to create a memory exploit scenario to check for security purposes.
(I just realised, I used “basically” in every single line of the above para. So, in my defence, yes, I was stressing on the basicness (if that is something). Ok, honestly, that’s because I’m super sleepy. XD)
And now, I’m going above to strike that one line. Because, I just somehow finished this blog for the sake of finishing it. I think I could’ve written it in a much better way.
But for now, this is what all I have. Next time, hopefully better. :)
Good night o/